
题目:《LiLT:一个简单而有效的用于结构化文档理解的语言无关布局转换器》
代码开源:https://github.com/jpWang/LiLT
提出一个适用于结构化文档和多语言文档的预训练模型,可以在单一语言上进行预训练,在其他语言上进行微调。
只使用文本和布局两者模态进行训练,文本部分可以使用RoBERTa/XLM-R/InfoXLM等进行文本特征的抽取;布局部分的模态,主要是使用本文提出的LiLT进行布局模态特征的提取。
创新点
- 提出了一个用于单语言/多语言进行结构化文档理解的模型LiLT
- 在模型中提出双向注意互补机制BiACM来进行文本与布局双模态之间的跨模态交互,以及两种新的预测任务来保证充分交互:关键点定位KPL和跨模态对齐识别CAI
- 在benchmarks上的实验证明了有效性。
算法流程
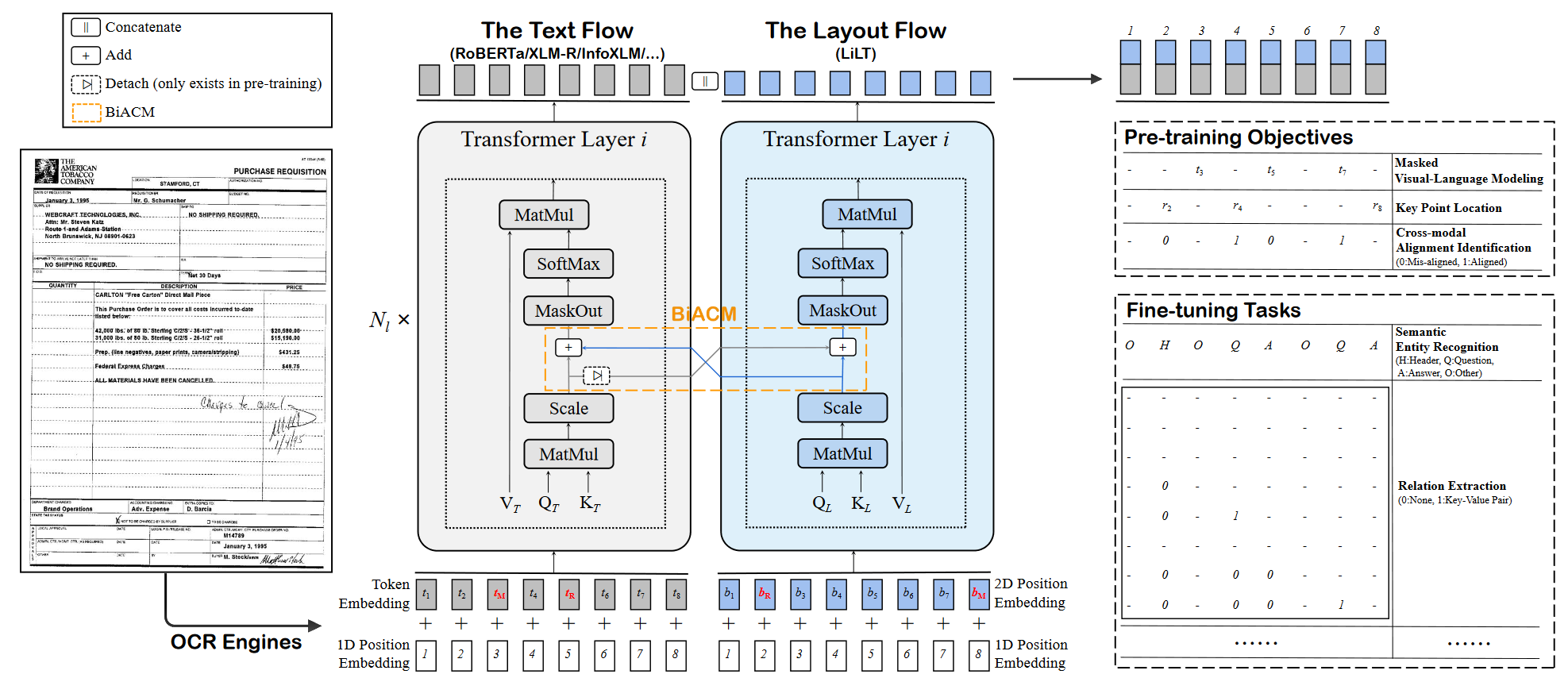 算法整体概述:
算法整体概述:
整体可以看作为是一个并行的双Transformer结构。首先,通过OCR工具获取文本的bounding box和内容的文本token,然后将文本和布局信息分别送入到对应的基于Transformer的架构来获得增强的特征,然后引入BiACM来进行文本与布局之间的跨模态交互,最终将编码好的文本和布局特征进行拼接,添加额外的头,最终进行自监督预训练或者下游任务微调。